
Posted on 11/17/2023 11:03:26 AM PST by ShadowAce
The most exciting thing about the Top500 rankings of supercomputers that come out each June and November is not who is on the top of the list. That’s fun and interesting, of course, but the real thing about the Top500 is the architectural lessons it gives us when we see new systems emerge on the Top500 and we get to see how choices of compute, memory, interconnect, storage, and budget all play out at a system level and across nations and industries.
We would normally walk through the top ten machines on the list and then delve into the statistics embodied in the Top500. This time around, we have assembled a more usable feeds and speeds of salient characteristics of the top thirty machines on the list, which we feel is representative of the upper echelon of HPC supercomputing right now.
But first, before we do that, it is appropriate to just review the performance development of the top and bottom systems that are tested using the High Performance LINPACK benchmark and the total capacity represented in the entire list between for the past thirty years that the Top500 rankings have been compiled.
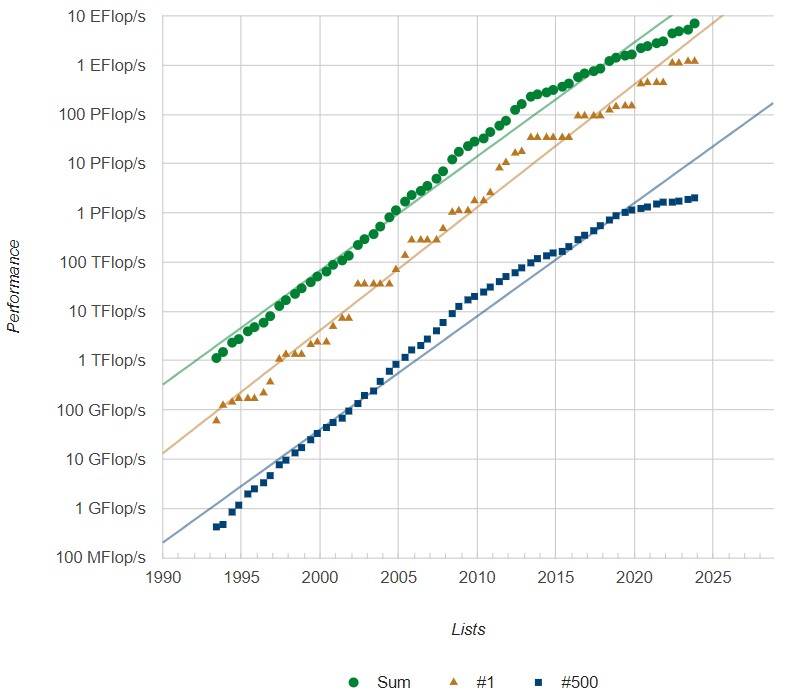
We have certainly strayed from the Moore’s Law curve that taught us to expect exponential performance increases. And it is fair to say that we have a very lopsided market – at least if you think those who submit HPL test results to the Top500 organizers are representative – with some very large machines comprising a large portion of the aggregate compute capacity on the list and a slew of relatively small machines that are nowhere near as powerful making up the rest.
A treemap of systems by architecture, created by the very clever Top500 database and graphing software, shows visually just how lopsided this is, with each square representing a single machine and each color representing a particular compute engine choice in the November 2023 rankings:
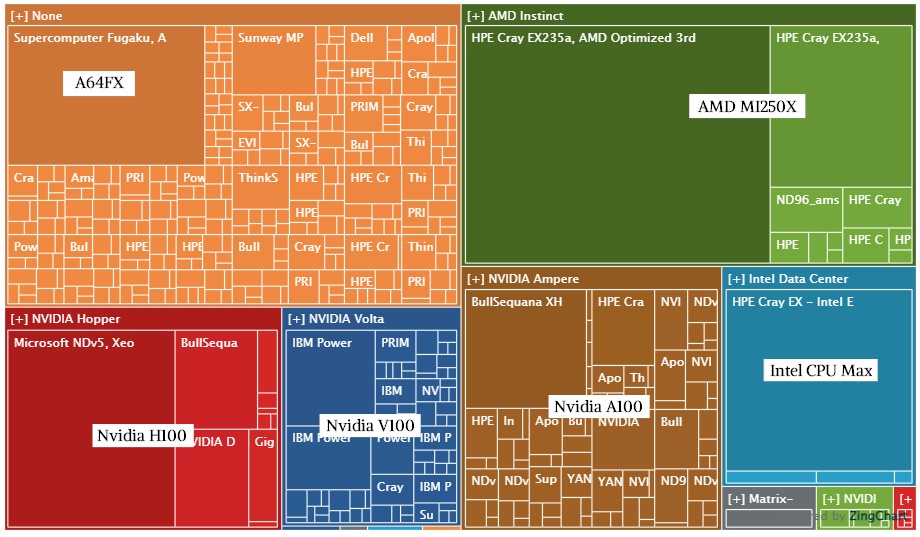
Going clockwise from the upper left, the big burnt orange square is the “Fugaku” system at RIKEN Lab in Japan based on Fujitsu’s A64FX Arm chip with big fat vectors. The olive green/brownish color in the largest square is the Frontier machine (hey, I see in color, I just don’t necessarily see the same colors you might) and the lighter version of this color is the AMD GPU neighborhood. The blue square at five o’clock is the half of the Aurora system that has been tested, and that purple area just below it is the “TaihuLight” system from 2016 based on the Sunway SW26010 processor (similar in architecture to the A64FX in that it is a CPU with lots of vector engines) at the National Supercomputing Center in Wuxi, China. The Nvidia A100 neighborhood is immediately to the left, with the “Leonardo” system at CINECA in Italy built by Atos being the largest square in this hood. The blue neighborhood at 6:30 as we move around is not just IBM, but includes the pre-exascale “Summit” machine at Oak Ridge and the companion “Sierra” machine at Lawrence Livermore National Laboratory. On the lower left you see that a new Microsoft machine called “Eagle,” which is running in its Azure cloud, is not only the third largest supercomputer in the official Top500 rankings but is also the largest machine using Nvidia’s “Hopper” H100 GPU accelerators.
As you see in the performance development chart above, the addition of some new machines among the top thirty machines has helped pull the average aggregate 64-bit floating point performance of the biggest 500 systems to submit results upwards. Notably, this includes the long-awaited “Aurora” supercomputer built by Hewlett Packard Enterprise with CPU and GPU compute engines from Intel and the Slingshot interconnect from HPE. Or rather, it includes around half of that machine, which has just a tiny bit over 2 exaflops of peak theoretical performance and which is, as happens with any new architecture, going through a shakedown period where it is being tuned to deliver better computational efficiency than its current results show.
The ”Frontier” system at Oak Ridge National Laboratory, comprised of custom “Trento” Epyc CPUs and “Aldebaran” MI250X GPUs from AMD all lashed together with HPE’s Slingshot 11 interconnect, remains the number one system in the world ranked by HPL performance. But there are two and possibly three different machines installed China that might rival Frontier and a fully tested Aurora machine. We have placed them unofficially on the Top 30 list, initially using the expected peak and HPL performance as assessed by Hyperion Research two years ago and then we just updated the table with better estimates of their current performance, so we can reflect reality a bit better.
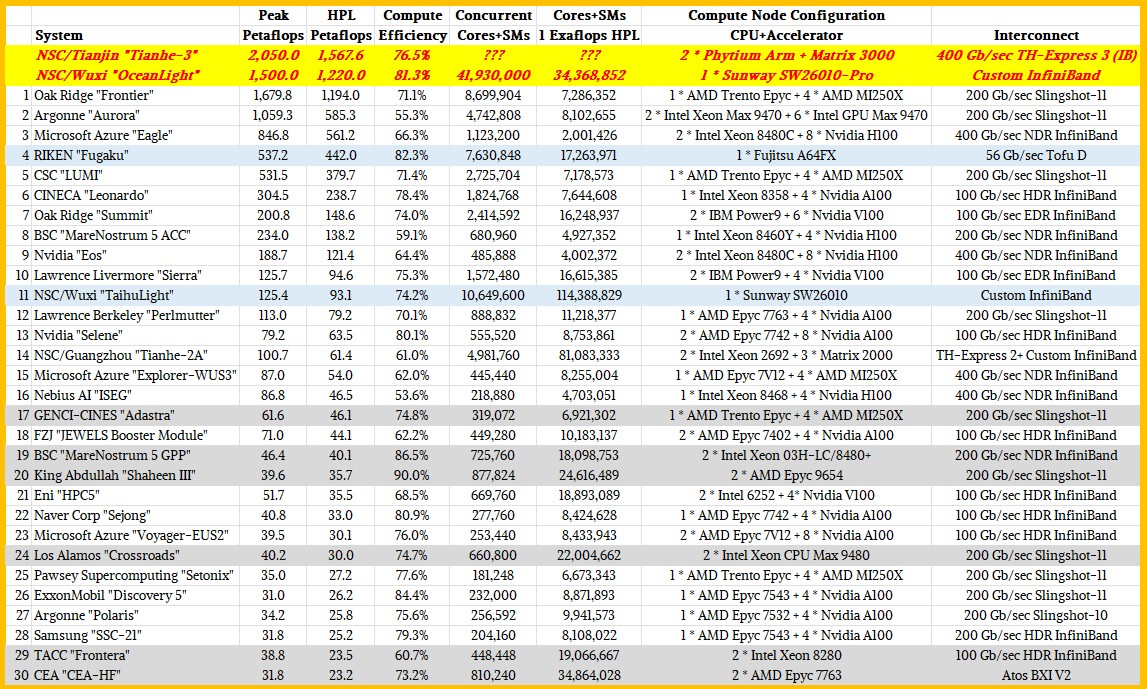
In the table above, the machines with light blue bars are using special accelerators that put what is in essence a CPU and a fat vector on a single-socket processor. Fugaku and TaihuLight do this, and so does OceanLight. The machines on the gray bars are CPU-only machines or partitions of larger machines that are only based on CPUs. The remaining 22 machines (not including the two Chinese exascalers in bold red italics and in the yellow bars) are based on hybrid architectures that pair CPUs with accelerators, and most of the time the accelerator is a GPU from either Nvidia or AMD.
If China published the test results for the “Tianhe-3” system located at the National Supercomputing Center in Tianjin, and if the rumors are right, then this machine has 2.05 exaflops peak performance and somewhere around 1.57 exaflops on HPL. And that would make it the number one system in the world for the past several years, as we reported two years ago before SC21. The OceanLight system at NSC/Wuxi weights in at 1.5 exaflops peak and around 1.22 exaflops on HPL as far as we can tell from rumor and double-checks based on several papers that have been published about this machine. That makes them both more powerful than Frontier.
Considering that the compute engines in supercomputers are all expensive, we are always particularly interested in the computational efficiency of each machine, by which we mean the ratio of HPL performance to peak theoretical performance. The higher the ratio, the better we feel about an architecture. This is one of the few datasets that allows us to calculate this ratio across a wide array of architectures and system sizes, so we do what we can with what we have, but we know full well the limitations of using HPL as a sole performance metric for comparing supercomputers.
That said, we note that at 55.3 percent of peak, the HPL run on the new Aurora machine – or rather, about half of it – was not as efficient as Argonne, Intel, and HPE had probably hoped. We estimated back in May of this year that with a geared down “Ponte Vecchio” Max GPU running at 31.5 teraflops, with 63,744 of them in the Aurora machine, would deliver 2.05 exaflops of peak. At that low computational efficiency, the Aurora machine fully scaled out would only hit 1.13 exaflops on the HPL test, which is less than the 1.17 exaflops that Frontier is delivering. At somewhere around 65 percent computational efficiency, Aurora should hit 1.31 exaflops, and at 70 percent, it could hit 1.41 exaflops.
We think Aurora will get more of its peak floating point oomph chewing on HPL as Intel and HPE test the machine at a fuller scale. This is Intel’s first version of its Xe Link interconnect, which used to hook the Max GPUs to each other and to the “Sapphire Rapids” Xeon SP HBM processors in each Aurora node. Nvidia has shipped its fourth version of NVLink and AMD is on its third version of Infinity Fabric. These things take time.
There are a few other machines in the top thirty of the November 2023 list that are below the average computational efficiency. And it is not like other machines didn’t start out at this level (or lower) before and sometimes even after their first appearance on the rankings. For instance, we heard a rumor as we were awaiting Frontier’s appearance that it was well under 50 percent computational efficiency, which is why we didn’t see it when we expected it. In this case, there was a new CPU, a new GPU, and a new interconnect that all had to be tuned up together at scale for the first time. Ditto for the accelerator cluster (ACC) portion of the “MareNostrum 5” system at Barcelona Supercomputing Center in Spain or the “ISEG” system at Nebius AI in the Netherlands.
We expect for CPU-only machines to be more efficient because there is one fewer layer of networking involved. And indeed, if you average the computational efficiency of the eight CPU-only machines in the top thirty, you get 77.1 percent of peak flops for HPL, while the accelerated machines average 70.3 percent.
There doesn’t seem to be a discernable pattern if you plot computational efficiency across concurrency, so it is not like higher orders of concurrency mean lower computational efficiency:
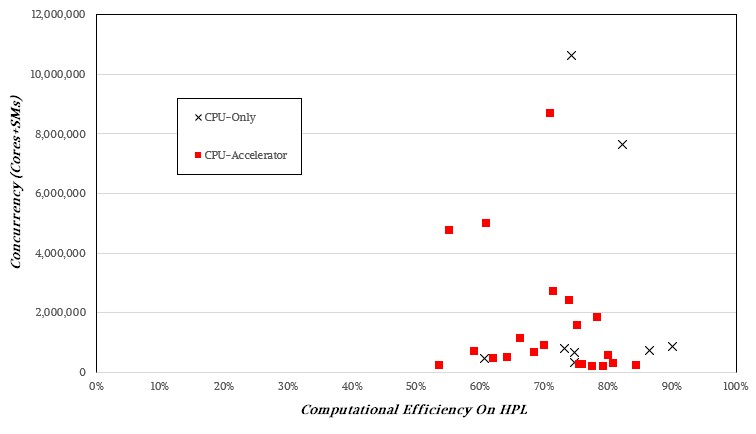 The CPU-only and hybrid architectures vary widely in their computational efficiency on the HPL test, and we strongly suspect this has as much to do with tuning experience as it does architecture. Very likely more.
The CPU-only and hybrid architectures vary widely in their computational efficiency on the HPL test, and we strongly suspect this has as much to do with tuning experience as it does architecture. Very likely more.
If you plot this on a log scale, there is no pattern that pops out, either.
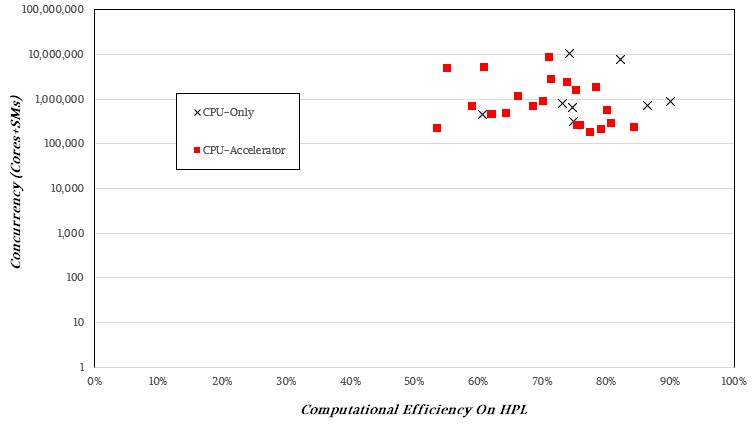 Sometimes, knowledge is knowing what something isn’t rather than what it is. Higher bandwidth and lower latency – and predictable latency at that – seem to be what drives performance. Anything above 75 percent is commendable, anything about 80 percent to 85 percent is amazing. And with 90 percent computational efficiency on the CPU-only “Shaheen III” cluster, we want to know what magic tricks the techies at King Abdullah University in Saudi Arabia are doing. We ain’t seen anything like that since the “K” supercomputer at RIKEN Lab a decade ago.
Sometimes, knowledge is knowing what something isn’t rather than what it is. Higher bandwidth and lower latency – and predictable latency at that – seem to be what drives performance. Anything above 75 percent is commendable, anything about 80 percent to 85 percent is amazing. And with 90 percent computational efficiency on the CPU-only “Shaheen III” cluster, we want to know what magic tricks the techies at King Abdullah University in Saudi Arabia are doing. We ain’t seen anything like that since the “K” supercomputer at RIKEN Lab a decade ago.
We would also like to know, of course, if there is any correlation between HPL performance and real HPC simulation and modeling workload performance. For a lot of workloads, the HPCG benchmark, which chews up exaflops and spits them out with just terrible levels of computational efficiency, is probably a better gauge. And that is a bitter pill to swallow.
Now they're aiming for ExaFlops.
Cool post about hardware. What about OS? :)
PetaFlops, ExaFlops, or whatever...
It’s all abut GIGO.
If what you put in is garbage, what you get out is garbage.
We have supercomputers doing the work for ‘climate change’ and for web searches, but, a large part of what we get is garbage, because, the people managing and putting things into those computers, are lefties with progressive ideas who only want to get the results which they have predefined.
If I remember China’s “great leap forward” in computing began after BJ Clinton opened up adanvanced computer sales to China.
Thanks, interesting.
LOL!
I believe that the Top500 is 100% Linux these days. I honestly have not looked for a while.
I was wrong--I just looked up the #1 system, and it's running HPE Cray OS.Here is a summary of the systems in the Top 10:
Frontier remains the No. 1 system in the TOP500. This HPE Cray EX system is the first US system with a performance exceeding one Exaflop/s. It is installed at the Oak Ridge National Laboratory (ORNL) in Tennessee, USA, where it is operated for the Department of Energy (DOE). It currently has achieved 1.194 Exaflop/s using 8,699,904 cores. The HPE Cray EX architecture combines 3rd Gen AMD EPYC™ CPUs optimized for HPC and AI, with AMD Instinct™ 250X accelerators, and a Slingshot-11 interconnect.
Aurora achieved the No. 2 spot by submitting an HPL score of 585 Pflop/s measured on half of the full system. It is installed at the Argonne Leadership Computing Facility, Illinois, USA, where it is also operated for the Department of Energy (DOE). This new Intel system is based on HPE Cray EX - Intel Exascale Compute Blades. It uses Intel Xeon CPU Max Series processors, Intel Data Center GPU Max Series accelerators, and a Slingshot-11 interconnect.
Eagle the new No. 3 system is installed by Microsoft in its Azure cloud. This Microsoft NDv5 system is based on Xeon Platinum 8480C processors and NVIDIA H100 accelerators and achieved an HPL score of 561 Pflop/s.
Fugaku, the No. 4 system, is installed at the RIKEN Center for Computational Science (R-CCS) in Kobe, Japan. It has 7,630,848 cores which allowed it to achieve an HPL benchmark score of 442 Pflop/s.
The (again) upgraded LUMI system, another HPE Cray EX system installed at EuroHPC center at CSC in Finland is now the No. 5 with a performance of 380 Pflop/s. The European High-Performance Computing Joint Undertaking (EuroHPC JU) is pooling European resources to develop top-of-the-range Exascale supercomputers for processing big data. One of the pan-European pre-Exascale supercomputers, LUMI, is located in CSC’s data center in Kajaani, Finland.
The No. 6 system Leonardo is installed at a different EuroHPC site in CINECA, Italy. It is an Atos BullSequana XH2000 system with Xeon Platinum 8358 32C 2.6GHz as main processors, NVIDIA A100 SXM4 40 GB as accelerators, and Quad-rail NVIDIA HDR100 Infiniband as interconnect. It achieved a Linpack performance of 238.7 Pflop/s.
Summit, an IBM-built system at the Oak Ridge National Laboratory (ORNL) in Tennessee, USA, is now listed at the No. 7 spot worldwide with a performance of 148.8 Pflop/s on the HPL benchmark, which is used to rank the TOP500 list. Summit has 4,356 nodes, each one housing two POWER9 CPUs with 22 cores each and six NVIDIA Tesla V100 GPUs each with 80 streaming multiprocessors (SM). The nodes are linked together with a Mellanox dual-rail EDR InfiniBand network.
The MareNostrum 5 ACC system is new at No. 8 and installed at the EuroHPC/Barcelona Supercomputing Center in Spain. This BullSequana XH3000 system uses Xeon Platinum 8460Y processors with NVIDIA H100 and Infiniband NDR200. It achieved 183.2 Pflop/s HPL performance.
The new Eos system listed at No. 9 is a NVIDIA DGX SuperPOD based system at NVIDIA, USA. It is based on the NVIDIA DGX H100 with Xeon Platinum 8480C processors,N VIDIA H100 accelerators, and Infiniband NDR400 and it achieves 121.4 Pflop/s.
Sierra, a system at the Lawrence Livermore National Laboratory, CA, USA is at No. 10. Its architecture is very similar to the #7 system’s Summit. It is built with 4,320 nodes with two POWER9 CPUs and four NVIDIA Tesla V100 GPUs. Sierra achieved 94.6 Pflop/s.
Buying Nvidia was one of my better ideas
I wonder why the charts show no systems with IBM’s new Power 10 CPU’s, only the prior Power 9’s?
Were told where I work if we replace our current Power 9 powered server with a similar size server with a Power 10 CPU and NVMe storage, our IPL time will go from 15 minutes to 35 seconds.
Of course the NVMe storage, successor to solid state, makes up a lot of that speed.
Yeah—I upgraded my 10-yo laptop from dual 5400rpm spinning disks to a new laptop running NVMe. Bootup time (IPL) went down to 18 secs from cold power off to logging in.
ANDDD... Windows still takes forever to load.
“I believe that the Top500 is 100% Linux these days.”
Cray has developed their own OS. Linux has some roles in it.
Thank you!
I've got an ancient HP all-in-one (which wasn't exactly a powerhouse when it was new) with Win10 on a PATA HDD (not SSD) that boots from stone cold to ready to type in 40 seconds. A lot of that is because of the AMD A8 slug.
DOS 3.2
Disclaimer: Opinions posted on Free Republic are those of the individual posters and do not necessarily represent the opinion of Free Republic or its management. All materials posted herein are protected by copyright law and the exemption for fair use of copyrighted works.