
Posted on 02/14/2005 5:29:01 PM PST by Quix
GREETINGS,
[The following posts are from the JAN/FEB BIBLE CODES DIGEST. I have their standing permission to post them on FR. The one to follow this one is an interesting discussion of codes seemingly about the “Da Vinci Code.” More to follow . .[“QxEmph”= Quix emphasis added] Some paragraphing was added when original paragraphs were long and included more than one significant topic.Quix]
Correspondence
Length of Bible Increases Chances
Your website stresses how unlikely it is that a cluster, such as the one found in Isaiah 53, would occur by chance, especially since the coded phrases correspond so closely with the meaning of the surface text. However, considering that the Bible is quite lengthy, consisting of approximately 1,500 pages, is it really that unlikely for such a cluster to appear by chance in one or more places in the Bible? Clearly, the longer the text, the greater the chances are for such anomalies to occur. If every page of the Bible contained such clusters, your premise would be quite compelling, but they do not.
The way to test the chances of such clusters occurring is indeed to analyze other works, and see how often these cluster anomalies occur, compared to how often they occur in the Bible. You could also perform the experiment on several or more randomly selected books of shorter length (than the Bible), which together, equal the length of the Bible. If the combination of books has more pages than the Bible, exclude the extra pages in the experiment.
I agree that one should not disregard the significance of smaller clusters that are also improbable, even though they are not as improbable as the Isaiah 53 cluster. The probability question is really this: What are the odds that all of the clusters found in the Bible, with due regard for their various lengths and densities, would occur in a text as long the Bible, (i.e., having the same number of letters as the Bible)? More generally, the question is: What does all of the data taken together tell us?
I am very anxious to read your new book!
Craig W. B
Wadsworth, OH
Director [of the “Isaac Newton Bible Code Research Society—publishers, originators of the BCD] Ed Sherman's Reply:
Thank you for your very thoughtful questions. We have tested a non-Biblical text, a Hebrew translation of Tolstoi’s novel, War & Peace, and have measured the probability of finding ELSs of different lengths within a non-encoded text, given how many ELSs have been searched for. This analysis [Link here: http://www.biblecodedigest.com/page.php/186 SEE POSTED BELOW THIS CORRESPONDENCE], along with parallel analyses of the Bible, form the basis of our claims.
You will find as you read the book that we deal with the question of text length carefully and, we believe, appropriately.
Your proposed probability question at the end of your e-mail is excellent theoretically, but is not feasible. The problem is that no program exists to do what you propose—because it would require, at a minimum, a program with the ability to take any string of Hebrew letters and to determine the longest portion of that string that represented intelligible, grammatically correct Hebrew phrases and/or sentences that appeared sequentially within that string. And it would also have to provide reliable translations of all the optimally lengthy strings from Hebrew to English.
Absent such a program, we must settle for the drawing of samples, the employment of a Hebrew expert and the application of probability estimation techniques. That is what we have done, and the results from the samples we have drawn from the Bible are so far beyond what chance could produce from a non-encoded text, that we should conclude that coding exists in the Bible.
Abstract
A set of 100 equidistant letter sequences (ELSs) were drawn, equally from the Hebrew text of the book of Ezekiel and a control text (a Hebrew translation of Tolstoy’s novel War and Peace). Each of these initial ELSs (that was the name of an Islamic nation) was reviewed for possible extensions by a Hebrew expert who was blind regarding the source text of each letter string. The number of extensions discovered in Ezekiel was more than 50% higher. A Markov chain model based on the indicated extension discovery rate from the control text (19.4%) was used to determine the expected range in the number of ELSs consisting of three or more extensions that would be discovered from the search for possible extensions around 295 initial ELSs in Ezekiel 37. Although only 5.95 ELSs consisting of three or more extensions were expected, 33 were actually discovered. The greatest number of ELSs with three or more extensions produced from 1 million trials of the Markov chain model simulation was 21. It is evident that the null hypothesis that the Ezekiel 37 findings were due to chance should be rejected.
A similar comparison was made assuming the much higher discovery rate (27.0%) indicated from the Ezekiel text of the Islamic Nations experiment. The null hypothesis was still rejected at the 0.001 level.
Introduction
In 1994 the paper, "Equidistant Letter Sequences in the Book of Genesis," was published in the journal Statistical Science. In it three Israeli mathematicians, Dr. Eliyahu Rips of the Hebrew University of Jerusalem, Dr. Doron Witztum and Yoav Rosenberg of the Jerusalem College of Technology, [QxEmph] described the results of an experiment in which the proximity of such sequences (ELSs) for related topics tended to be in closer proximity in the book of Genesis than in randomized re-orderings of that text. The ELSs studied were the names of 66 of the most famous rabbis in Jewish history and their dates of death or birth. ELSs are formed by eliminating the spaces between words in the Hebrew text of the Old Testament and then by selecting every n-th letter from the compacted text, where n is the skip of the ELS. For example, within the letter string n e w j e r s e y, "wes" is an ELS with a skip of +2 and "sewn" is an ELS with a skip of –2.
Once an initial ELS such as "wes" has been found at a given skip, an extended ELS can be sought by continuing to extract letters from the literal text at the given skip of the initial ELS. From the sentence, "People say New Jersey was wonderful," the following search string around the "wes" ELS is extracted:
The word "yawn" appears after "wes" in the string, but this is rejected as a valid extension since it doesn’t form a proper phrase in English. If the second to the last letter in this string had been a "d" instead of an "f," "yawned" would have been a valid extension of the "wes" ELS.
In 1997 Michael Drosnin authored the book, The Bible Code, which topped the New York Times best seller list for many weeks. An atheistic Jew, Drosnin claimed that the Bible was filled with ELS codes about numerous current events and that this was proof that some super-human intelligence who knew the future, had written the Old Testament.
Numerous mathematicians have argued heatedly that the Witztum Rosenberg Rips paper was flawed while others have staunchly defended it. [QxEmph] Drosnin’s book was repudiated by Dr. Rips, and dozens of mathematicians, since it presents dozens of trivial examples that are so simple that comparable examples could be extracted from any Hebrew book or random sequence of Hebrew letters.
Four years ago Mr. Sherman began examining this phenomenon, strongly suspecting that there was nothing to it. [Qx Emph] After developing formulae to estimate the probability of chance occurrence of different purported Bible code phenomena, he concluded that virtually all examples from published books were not at all improbable. A few published examples were borderline in terms of improbability, so the help of a Hebrew expert, Dr. Nathan Jacobi 2 , was sought to enable the search for more extensive ELSs in the same vicinity as the published examples of Hitler codes from Genesis 8 (from Drosnin) and Jesus codes from Isaiah 53 (from Christian author Grant Jeffrey). Dr. Jacobi discovered numerous lengthy ELSs in the Isaiah 53 cluster.
Mr. Sherman was forced to reverse his negative position on Bible codes, which he had been presenting on a website, and he changed the site to biblecodedigest.com. During April 2003 this website received 1.3 million hits as the result of interest generated by the war in Iraq and the posting of hundreds of ELSs regarding current events on that site.
In the past two years our research team has located over 120 lengthy ELSs by starting with short initial ELSs of key words about current events, centering on the terrorist attacks and related developments, that are all located in the 37th chapter of Ezekiel. The initial formulae were too simple to gauge the probability of chance occurrence of a code cluster as extensive as the one in Ezekiel 37, so another estimation approach was developed and applied. It is presented in this paper.
The Islamic Nations ELS Extension Experiment
To directly address the question of the purported validity of Bible codes, there has been a clear need for an impartial comparison of a collection of Bible codes with a parallel set of codes from an admittedly ordinary book. This paper presents the results of this experiment. Dr. Jacobi was given 100 pre-defined initial ELSs, equally drawn from the Hebrew text of Ezekiel and from a Hebrew translation of Tolstoy’s War and Peace. Dr. Jacobi searched for extended ELSs around each initial ELS—absent any knowledge of the source of each letter string. The two collections of extended ELSs were then compared and analyzed. This is the first such experiment of this type we have conducted.
Using the Hebrew spellings of a group of Islamic nations3, INBCRS researchers 4 located ELSs (with the five shortest skips) of these names of nations in a 78,064-letter portion of War and Peace and the 74,500-letter book of Ezekiel 5 provided with Codefinder software 6 .
Dr. Jacobi was sent five occurrences with the shortest skips from Ezekiel (and five occurrences from War and Peace) of the name of each of the Islamic nations as an ELS. He was asked to document whether letters before and after the terms created longer terms. Throughout the experiment, and up until June 2003, Dr. Jacobi has not known which of the initial ELSs and surrounding letter strings were from which source text.
The experiment was conducted from August 2002 through January 2003 by intermittently including portions of both sets of letter strings. Dr. Jacobi never knew when we started doing so and when we finished. We continued to submit to him our regular supply of letter strings from other parts of the Bible on other topics as part of a number of research projects. His task was always the same—to indicate whether letters before and/or after the terms created longer terms. During that period approximately one-third of letter strings he examined were part of the experiment.
All ELS extensions found around 50 initial ELSs in Ezekiel and 50 initial ELSs in War and Peace were examined and recorded. An extension is a phrase or brief sentence that appears entirely on one side of an existing ELS. The extension must represent a grammatically reasonable continuation of the existing ELS. As such, it could either incorporate part of the existing ELS or be a stand alone phrase or sentence that could reasonably precede or follow the existing ELS.
The average extension found in this experiment consisted of two Hebrew words that totaled seven letters. It is of course possible to find several extensions around an initial ELS to form one lengthy final ELS. For example, the following 53-letter-long ELS from Ezekiel 37 was formed by eight extensions found around the initial ELS of the Hebrew word for "combat":
1) The island was restful, elevated
2) and it happened.
3) Where is Libya?
4) And you have disrupted the nation.
5) She changed a word.
6) He answered them with combat.
7) Why the navy
8) and the smell of the bottom of the sea?
Table 1 provides a comparison of the search results on three different bases.

Appendix A provides a listing of all ELS extensions found in both search texts.
A key statistic estimated in this experiment is the ELS extension discovery rate. It is defined as the ratio of the actual number of extensions found to the number of opportunities available for finding an extension. At the beginning of each search of a new letter string, there are two opportunities to find an extension—one before the initial ELS and one after. If an extension is found, one new opportunity to find yet another extension is created. That opportunity will consist of the new letters that are now next to the extension that had just been discovered. There is no new opportunity on the other side of the ELS where an extension wasn’t found, since that opportunity has already been counted.
The discovery rate in the control text was 19.4% (=24/124). In Ezekiel, it was 27.0% (=37/137), which is 39.2% higher7. A standard statistical test of the null hypothesis that there is no difference in the underlying discovery rates (proportions) indicated that there was a 12.35% probability that the indicated difference could be due to chance. Therefore, the null hypothesis held up at the 0.10 significance level.
It has been our observation in the last four years of investigation that, if anything, the difference in the discovery rates is generally greater than the 8.1 %-age points indicated in this experiment, and appears to be in the range of 10% to 15%. If the 8.1 %-age differential were to hold up under a larger sample of initial ELSs, then the probability of chance occurrence of a differential as large as 8.1 % would drop below standard thresholds.
For example, if the names of 82 (rather than 50) Islamic nations were included in the experiment, the differential were to remain at 8.1%, then p would drop below the 0.05 significance level. If the names of 140 Islamic nations were included, p would drop below the 0.01 significance level. This possibility suggests the potential value of expanding the sample size in an enlarged version of this experiment. Of course, it is possible that the addition of more initial ELSs might result in a diminution of the differential.
The possibility that differences in letter frequencies between the two texts might account for some of the difference in discovery rates was considered. A visual comparison of the individual letter frequencies indicated a very strong similarity between the two texts. The correlation between the two sets of frequencies was quite high (0.964827).
The services of another Hebrew expert, Moshe Shak, a Canadian engineer, were retained to investigate the degree to which the indications might be affected by differences in translations between Hebrew experts. The results are displayed in Table 2.
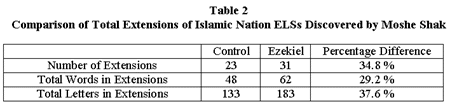
The discovery rate from Shak’s War and Peace extensions (18.7%) was very close to, but somewhat lower than, that from Dr. Jacobi’s extensions (19.4%).
1 R. Edwin Sherman is a Fellow of the Casualty Actuarial Society and a Member of the American Academy of Actuaries. He received a B.A. and M.A. in Mathematics from the University of California at San Diego, and passed three Ph.D. qualifying exams. He has 30 years of experience as a consulting actuary in serving numerous Fortune 500 corporations, major public entities, law firms and insurance companies in applying probability, statistics and econometric forecasting to risk management problems. He was a Principal with Pricewaterhouse Coopers, the world’s largest accounting and consulting firm, for seven years. He has authored five professional papers in actuarial journals and over 70 articles in trade publications. He directs the biblecodedigest.com website. 2Dr. Nathan Jacobi was educated in Biblical and contemporary Hebrew in Israel. He holds a B.Sc. in Mathematics and an M.Sc. in Physics from Bar-Ilan University. He received a Ph.D. in Physics from the Weizman Institute of Science. He has over 20 years of experience in research, development and scientific computing in applied physics, aerospace and geophysics. He currently teaches an intermediate Hebrew class in Ashland, Oregon. 3Algeria, Abu Dhabi, Bahrain, Dubai, Kuwait, Lebanon, Libya, Qatar, Somalia, Sudan and Yemen. Major islamic nations (Iraq, Iran and Saudi Arabia) were excluded because they had already been the subject of ELS extension searches in the book of Ezekiel. Originally only 10 nations were selected. However, for two of them less than five total ELSs were found, so Somalia was added to bring the total number of ELSs examined up to 50 for each text. 4Isaac Newton Bible Code Research Society. Researchers included Mr. Sherman, Dr. Jacobi and Mr. David Swaney. 5The final search text used extended from Jeremiah 51:52 through Ezekiel to Hosea 1:9. The last chapter from Jeremiah and the first chapter of Hosea were first added to expand the search text, and then as many final verses from the second to last chapter of Jeremiah were added as were needed in order for the Ezekiel Plus search text to have the same size (approximately) as the War and Peace search text. 6www.research-systems.com. 7The 39.2% differential for the discovery rates is lower than the 54.2% differential in the total number of extensions. This occurs because the denominators of the two discovery rates are not the same. Each new extension opens up a new opportunity to find yet another extension. Hence, there were many more opportunities to find new extensions in Ezekiel because more extensions were initially found in Ezekiel.
CONTINUE AT:
Please read the rest of the article here: http://www.biblecodedigest.com/page.php/187
Blessings to all fair-minded folks who wish to discuss it.
Frankly, the rabid naysayers are welcome to--as mother might say--go chase a duck; suck rocks or go fly a kite.
Is it possible that what we have is the encryption of a higher level story which is then contained, more or less, within the bounds set by a far more ancient but well known story?
Might be worth a look at the "originals" to determine where the additive parts might be.
"So, in other words, you bless only those who agree with you on the nonsense of "Biblic Codes" and curse those who disagree. "
That's the way it usually works.
The 'bible code' is a load of dung. It's so ridiculous that it looks like someone was playing a practical joke to see how many people would fall for it.
The Bible(s.) The most perfectly flawed and perfectly compelling documents ever authored since human memory was wiped clean 6 thousand years ago, give or take hundreds of years.
Humbug!
Haven't you got better things to do with your time (life) as well?
Prior to that folks learned (and remembered) immense bodies of information using what the Jesuits called a "Memory Palace". Noah's Ark, of course, was one ~ and though we have the basic dimensions of the vessel we no longer have the basic descriptions of each of the many tens of thousands of animals on board ~ Moses took care of that part, FUR SHUR, and today we have folks looking for a wooden boat in the mountains when they should, instead, be striving to recover the animal tales.
That the oldest parts of the Bible may well be repositories of encrypted information is not beyond belief. After all, the original "data dump", from oral to written form, had to have had encrypted references so you could keep it all straight. On the other hand, to claim that the information refers to the future is a tad questionable.
man, what are you? Epilectic? Don't you believe in paragraph breaks?
This is the latest installment on exploring and analyzing the phenomena. As I recall, nothing even close to a mosaic has EVER been found in ANY other Hebrew text--that is--nothing that has the same sort of appearance of something theologically sound and supernaturally coded. To my layman’s mind, some of them have been beautiful and awesome in their simplicity and in their faithfulness to Biblical theology—especially regarding Christ’s deity etc. Yet, it’s been troublesome and frustrating not to be able to assess them scientifically compared to chance.
I realize it’s not fashionable for seemingly most naysayers to actually read the quality research in support of the codes. But I hope that even skeptics will look at the mosaic type of codes fair-mindedly and closely. In any case—here’s this section of the latest Digest]
Bible Code Digest January/February 2005
The Controversy Over Mosaics: Round Five
Given a Hebrew word, a search text and a range of skip sizes, leading code software will instantly tell you how many times ELSs of that word will appear—by chance. What are we to make of instances where there is a large difference between the expected number of occurrences and the number of times the given ELS actually appears? And what if large differences occur for many different skip size ranges? When that happens, we call it a "mosaic."
Now, we aren't talking about an ELS that is only expected to appear one or two times in the search text. We're talking about ELSs that are expected to appear 50 or 500 or 5,000 times—because the ELS only consists of a few letters.
Let's look at an interesting example. Take the Hebrew word Eckad (alef-khet-dalet), which means "one." It is undoubtedly one of the most significant words in the Jewish faith. It appears at the end of the Shema of Deuteronomy 6:4 ("Shema Yisrael! Adonai Elohenu Adonai Eckad" or "Hear O Israel! The Lord is our God, the Lord is one.").
This places it at the heart of Judaism and its belief in a single, living God. Within the first 17 chapters of Genesis, the three-letter-long Eckad ELS consistently appears much more often than expected by chance over all but one range of skip sizes, as shown in the following table.
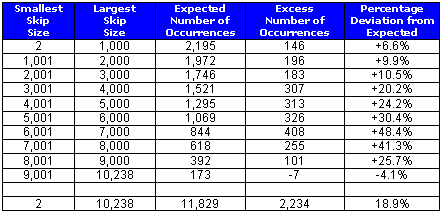
For example, the Eckad ELS appears 1,252 times with skips between 6,001 and 7,000 within Genesis 1-17, even though it is only expected to appear 844 times. That it should appear 48.4% more often than expected by chance seems highly unlikely. The following graph summarizes the above results.
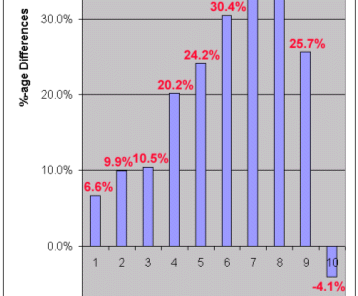
Mosaics differ from traditional ELS findings in a number of key ways. First, for mosaics, the shorter the ELS, the better; while for traditional ELSs, the longer the ELS, the better. Second, a broad range of skip sizes is included in a mosaic; whereas, for traditional ELSs, typically the focus is only on the occurrence with the shortest skip, or those with the shortest skips.
The phenomenon of mosaics has been covered in seven past issues of BCD. These issues cover key parts of the introduction and debate over the potential reality of this kind of Bible code phenomena. (To view Digests prior to January 2002, click on Subscribers and log on with your user name and password. Then, scroll to the bottom of the page and select the Digest you would like to view. We have provided links in the text below for Digests after January 2002.)
Quix note: Go here at the BCD site:
Here: http://www.biblecodedigest.com/page.php/288
In the November and December 2000 issues, BCD introduced the concept, much as was done above. Questions were raised by skeptics, who asserted that mosaics are simply caused by dramatic differences in letter frequencies between various parts of the search text.
What was the problem? Take the Eckad mosaic, for example, and let us assume that Genesis 1-17 is 20,000 letters long (it is actually slightly longer). Within that search text, the Eckad ELS with the longest possible skip would be one where the letters were the 1st, the 10,000th and the 19,999th.
Now consider all Eckad ELSs with skips of 9,000 to 9,999. The first possible such ELS would cover letters 1, 9,001 and 18,001 and the last possible such ELS would cover letters 2,000, 11,000 and 20,000. Thus, all of the letters of the Eckad ELSs in this skip size range appear in three ranges: 1-2,000, 9,001-11,000 and 18,001-20,000.

Given this, none of the Eckad ELSs with skips in this size range would include any letters in the ranges of 2,001-9,000 and 11,001-18,000. This would mean that none of the Eckad ELSs would draw from the 7,000 letters in the first range of text or from the 7,000 letters in the last range of text. Now suppose that the frequency of alefs, khets and dalets within those 14,000 letters of the literal text were dramatically less than in the ranges of the 6,000 letters from which the Eckad ELSs with skips of 9,000 to 9,999 had to be drawn. Then this would cause, all by itself, a seemingly dramatic mosaic effect within that skip size range.
At first glance, the above concern seemed to discredit the purported significance of mosaics of any kind. For some skeptics, their work had been done, and the whole thing could be dismissed. Looking further, however, there were various considerations that argued against dismissal:
• First, the above concern is quite small for small skip size ranges. It does, however, grow for each category of successively longer skips.
• Second, BCD presented the results of a study of the relationship between the relative meaningfulness of different ELSs and how strong the mosaic effect was within Genesis 1-17 ( February and March 2002 issues). The more often a given Hebrew word appeared in the literal text of the Bible, the more "meaningful" it was judged to be. And the greater the percentage variations of the actual number of occurrences were from the expected number, the more pronounced was the mosaic effect.
This strong relationship restored some credibility to the concept after criticisms posed by skeptics. Nevertheless, the whole phenomenon was a bit complicated in the first place, and it didn't help to have to offer complex explanations for why it was still worth noting, even though its existence could be shown, in many instances, to be significantly due to seemingly chance variations in letter frequencies between different parts of the search text.
• Third, in the January 2001 issue, BCD put forth the concept of the author of the Bible as an incomparable chess master who had deliberately built in the major differences in letter frequencies between subsections of a search text in order to create the presence of mosaics for some ELSs. This concept was bolstered by the strong correlation between ELS meaningfulness and the strength of its mosaic effect.
In the September 2002 issue, we noted the presence of the significant David mosaic in 1 Samuel.
In the October 2002 issue and the January 2003 issue, we reported on some of the research conducted by David Bauscher in the Aramaic New Testament (the Peshitta). In the September 2003 issue, we reported on yet more of Bauscher's research, reviewing results for 29 different divine names as ELSs.
In the fall of 2003 and the winter of 2004, a number of Bible code researchers focused on quantifying the primary weakness of the mosaic phenomenon, and searched for solutions to addressing this weakness. The basic problem, as detailed above, was this: the higher the skip size, the greater the proportion of the search text that would never be accessed by any of the ELSs within a given skip size range. And yet, when code software computes the expected number of occurrences, it uses the letter frequencies for the entire range of the search text.
Bauscher set forth a potential solution for this—mosaic searches should be done using a wrapped text. In such a text, when you come to the end of the literal text, you start all over with another copy of that text. This approach is analogous to treating the search text as a cylinder rather than a long straight line. Using a wrapped text fully eliminates the valid concern of skeptics. For each skip size range, all ranges of the letters of the original search text were equal candidates for being part of the selected ELS. So, there is no longer any bias in the estimation of the expected number of occurrences of the given ELS with skips in a specified skip range.
TO BE CONTINUED
Thanks for the ping!
Many fair-minded people understand that this whole Bible Code stuff is akin to numerology and not appropriate for understanding the Bible.
Then such people don't know how to read a dictionary very well or know nothing about the Bible Codes.
There is NOTHING similar to Biblical or other types of numerology to the Bible Codes.
I'd have thought you'd have known that.
BTW,
I personally do not think that the authentic codes have a great deal to do with understanding The Bible.
I believe they are a number of things
1) God's play. I think He's having fun confounding man's pontifical, arrogant wisdom.
2) God is affirming His timeless majesty with them.
3) God is providing for some sorts of skeptics grounds for considering the claims of The Bible.
4) Given that they affirm the basic doctrines of The Faith--INCLUDING THE BIBLICAL STANDARD THAT CHRIST CAME IN THE FLESH ETC. AND THAT they are inherently integral to the TEXT OF GOD'S WORD, they must have the same origin as the surface text--HOLY SPIRIT. I personally try to be very cautious about throwing rocks at Holy Spirit's work.
Quix, you said, 'I personally try to be very cautious about throwing rocks at Holy Spirit's work.' Well put.
/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/
May ALL those who fear the Lord take care not to:
1. Say that something is not of God that actually is of God,
2. Say that something is of God that isn't.
/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/
Thanks for all your great work, Quix! The Lord recompense thy work, and a full reward be given thee of the Lord God of Israel, under whose wings thou art come to trust.
JM
1 John 3 MSG: 13. So don't be surprised, friends, when the world hates you. This has been going on a long time.
WELL SAID.
As a well experienced counselor, such should no longer surprise me as much as it does.
Sometimes I still have this delusional thinking that believers should be quite logical.
When, actually, the attitudes of their hearts and their personality dynamics decide a lot more theological and other issues than logic does.
But, Christ seemed to know that when He walked around dealing with the very religious, as well.
Please let me know if you believe you have any Spirit born sense, hunch, insight.
Blessings,
Disclaimer: Opinions posted on Free Republic are those of the individual posters and do not necessarily represent the opinion of Free Republic or its management. All materials posted herein are protected by copyright law and the exemption for fair use of copyrighted works.