A few days ago, there was an interesting thread on Hacker News about the strange things Xerox WorkCentre copiers can do to a document. The HN thread was prompted by this blog post and dealt strictly with the technical merits, uncontaminated by conspiracy theory.
From the blog post:
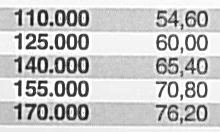
Next example: Some cost table, scanned on the WorkCentre 7535. As we are used to, a correct-looking scan at the first glance, but take a closer look. This error was found because usually, in such cost tables, the numbers are sorted ascending.
Before After The 65 became an 85 (second column, third line). Edit: I'm getting emails telling me that also a 60 in the upper right region of the image became a 80. Thanks! This is not a simple pixel error either, one can clearly see the characteristic dent the 8 has on the left side in contrast to a 6. This scan is several weeks old – no one can say how many wrong documents have been produced by the Xerox machines in the mean time.

The consensus of Hacker News posters was that the errors were due to improper use of the JBIG2 compression algorithm. One of the HN posters claimed to be the author of Google Books' JBIG2 compressor:
agl 7 days ago | Post #12
This class of error is called (by me, at least) a "contoot" because, long ago, when I was writing the JBIG2 compressor for Google Books PDFs, the first example was on the contents page of book. The title, "Contents", was set in very heavy type which happened to be an unexpected edge case in the classifier and it matched the "o" with the "e" and "n" and output "Contoots".The classifier was adjusted and these errors mostly went away. It certainly seems that Xerox have configured things incorrectly here.
Also, with Google Books, we held the hi-res original images. It's not like the PDF downloads were copies of record. We could also tweak the classification and regenerate all the PDFs from the originals.
For a scanner, I don't think that symbol compression should be used at all for this reason. For a single page, JBIG2 generic region encoding is generally just as good as symbol compression.
More than you want to know about this topic can be found here: https://www.imperialviolet.org/binary/google-books-pdf.pdf
Ranted another poster:
linohh 7 days ago | Post #35
This was predictable. JBIG2 is in no way secure for document processing, archiving or whatsoever. The image is sliced into small areas and a probabilistic matcher finds other areas that are similar. This way similar areas only have to be stored once.Yeah right, you get it, don't you? They are similar, not equal. Whenever there's a probability less than 1, there's a complementary event with a probability larger than 0.
I wonder which prize idiot had the idea of using this algorithm in a copier. JBIG2 can only be used where mistakes won't mean the world is going to end. A photocopier is expected to copy. If the machines were used for digital document archiving, some companies will face a lot of trouble when the next tax audit is due.
Digital archives using this kind of lossy compression are not only worthless, they are dangerous. As the paper trail is usually shredded after successful redundant storage of the images, there will be no way of determining correctness of archived data.
This will make lawsuits a lot of fun in the future.
The point is that modern scanners and copiers don't just output raster scans. Rather, they analyze the image heavily in order to encode it for compression and OCRing. That sort of activity explains the anomalies of Zero's BC PDF, not some absurdly clumsy attempt at forgery.